We introduced Cockroach Labs last June with a simple yet ambitious mission: Make Data Easy.
```We’ve spent the intervening months moving CockroachDB from an alpha stage product to launching CockroachDB beta. In the process, the team has nearly tripled in size and development has accelerated to a blistering pace. We’ve supplemented our original investment led by Peter Fenton of Benchmark with an additional round of funding, led by Mike Volpi of Index Ventures. We’re lucky to also count GV (formerly Google Ventures), Sequoia, FirstMark, and Work–Bench as investors.
Why CockroachDB?
It’s bog standard in our industry for the data architecture you start with to remain the one you still have in five years, love it or hate it. In light of this, it makes sense to choose your initial architecture carefully as it can save tremendous resources down the road. Our goal in building CockroachDB was an open source database better suited to the fast-evolving challenges that companies will face over the next decade. We believe those needs encompass three crucial capabilities: scalability, survivability, and SQL, while always maintaining strong consistency.
Scalability
The data underlying most businesses continues to expand faster than traditional databases can keep up with. The challenge goes beyond what’s immediately obvious. It turns out that data has no trouble expanding to fill available capacity: most companies are busy collecting data on their data! With data growing faster than improvements to the underlying database hardware, horizontal scalability is a requirement.
Survivability
In today’s leveraged business environment, downtime has never been so expensive. A SaaS company with 500 enterprise customers experiencing a five minute outage is actually causing 2,500 minutes, or nearly two days of disruption. A database should survive even datacenter outages, and it should do so without manual intervention and with perfect data fidelity (strong consistency).
SQL
SQL is the lingua franca of the database world. Or at least it was for about 35 years until 2004, when Google announced a new database called BigTable which eschewed the old standards in pursuit of simplicity and scalability. BigTable and the many databases which followed in its footsteps never envisioned or agreed on a consistent API for developers. It’s our industry’s own tower of Babel, with similar results. But providing a common standard is not all SQL is good for, especially as project complexity increases. Developers need transactions and well-defined schemas, and while many database users are able to write SQL queries, they may not be able to program map reduces. SQL has been getting the job done for 45 years now, it’s widely understood, and it’s a platform in its own right, with a substantial ecosystem of tools and educational resources built around it. For these reasons, we believe it’s the most productive API, and our ongoing challenge is to make it work well enough to justify that claim.
The Road to CockroachDB Beta
In addition to our open source contributors, Cockroach Labs currently has more than 20 full time employees building CockroachDB. The system has been evolving so quickly that it’s become increasingly difficult to keep up. The project has rapidly matured in functionality, stability and performance over the past three quarters.
Our original intent was to deliver the beta end of summer last year, as a transactional key-value store. We reconsidered after becoming convinced that SQL was a necessary part of CockroachDB’s identity. The consensus was that without it, developers would end up having to build too much of the missing functionality themselves. We also worried about missing the opportunity to precisely define CockroachDB, instead leaving our users with more questions than answers. Will it have SQL eventually? Is it NoSQL? Am I supposed to build my own indexes?
The decision to include SQL in our beta release added two quarters to our timeline. And before you wonder how that’s possible in only two quarters, it’s important to note that we stopped short of supporting joins or of parallelizing the execution of distributed SQL queries. Nevertheless, the stage is set: we are a scalable SQL database. The beta SQL support is a functional and appropriate starting point.
What Does “Beta” Mean?
We’re deliberately announcing a beta for CockroachDB because nothing is better than supporting real world use cases to sharpen focus and efficiently direct resources. ”Beta” means software with more bugs and potential performance or stability issues. That’s a pretty good description of CockroachDB right now, and this is the expectation we’d like you to start with. However, the key differentiator of CockroachDB beta from our alpha release is a commitment that future changes will be backwards compatible.
What’s in CockroachDB Beta?
We’re excited to announce that this beta release contains nearly everything found in the original design document and many previously-unanticipated features, not least of which is the addition of SQL. Crucially, everything necessary to support scalability, survivability, and strong consistency is in place. The system self organizes without requiring external services, self heals as nodes are lost or damaged, and automatically rebalances to maintain equilibrium as new nodes are added.
We provide distributed transactions with serializable and snapshot isolation and have implemented an online schema change system that allows indexes to be added without requiring any downtime or table locking. We’ve also added extensive support for keeping time series of metrics including op latency and counts, network and disk I/O, and host memory and cpu usage. We surface this information to operators through our fast-evolving administrative UI:
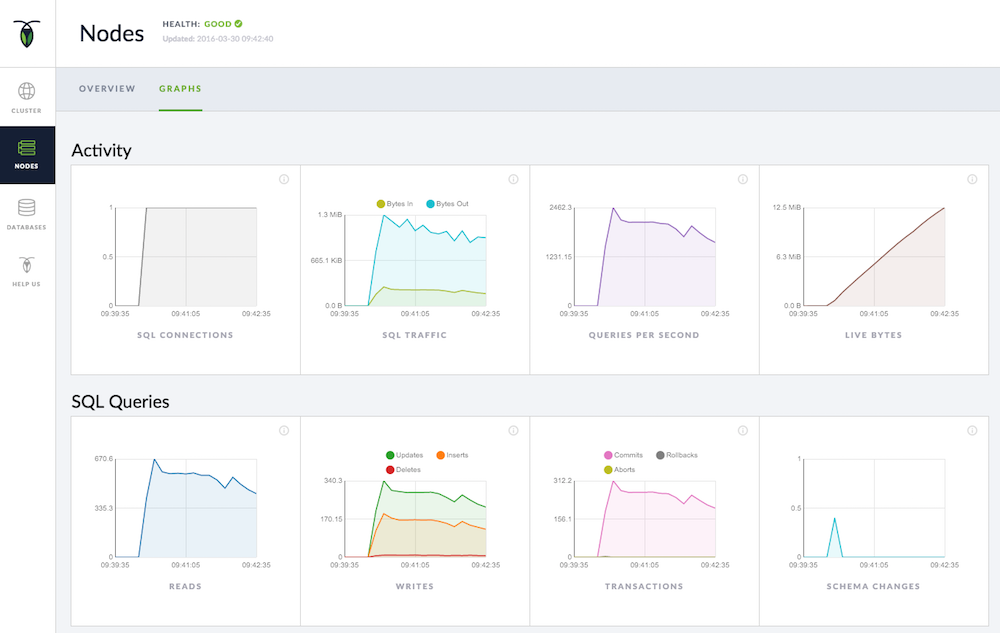
One of the most notable features of CockroachDB is just how simple it is to deploy. CockroachDB is a single binary which requires only the location of one or more storage devices to manage. Starting a multi-node cluster is as simple as starting the first node on its own and then pointing each additional node at the first node or any other node which has already joined the cluster. There are no external dependencies required. No global configuration, no distributed file system, no bundle of resources or install scripts. There are no config files and we’ve strictly limited the available command line flags to those which are useful and not just tunable knobs for the sake of having knobs. Securing a cluster is similarly straightforward.
What Comes Next?
For those of us working on The Roach, this is where the fun truly begins. We’re proud to have implemented a design with such promise for building the next generation of products and services. We can’t imagine a future without a sane, scalable, and performant database solution, and we intend to build it. CockroachDB is meant to work as well for a three-node cluster as a Silicon Valley data farm, and to provide a straight path between the two.
In the near future we’ll focus on expanding the SQL capabilities to include joins and distributed query execution; we’ll continue to add better production and administration features; and we’ll improve stability and performance. True success will mean CockroachDB joining the ranks of other open source platforms and geek household names like Postgres, MySQL, and Hadoop. We think we’re on to something here and can’t wait for new users to help shape the direction.
Download the CockroachDB beta, deploy a test cluster, and build a test app. The team is committed to supporting new users and debugging issues as they arise, so please don’t hesitate to contact us with questions or concerns. The best way to ask questions in real time is in the CockroachDB Slack Community. If you’d like to file an issue or feature request, please use our GitHub issues.
Happy Roaching!